Infos zu MiMoText auf der vDHd 2021
Herzlich willkommen auf der Seite zu unserem Beitrag für die vDHd2021!
Worum geht es in “MiMoText in sechs Stationen”? Dazu steht bereits einiges in der Ankündigung der vDHd-Seite. Eine kurze Projektbeschreibung findet sich hier.
Audio-Ankündigung im RadiHum-Podcast anhören
Team: Maria Hinzmann, Universität Trier (MariaHinzmann) | Katharina Dietz, Universität Trier | Katharina Erler-Fridgen, Universität Trier | Anne Klee, Universität Trier | Julia Röttgermann, Universität Trier | Moritz Steffes, Universität Trier | Christof Schöch, Universität Trier
Wann: 24.3.2021, 10:00-12:00 Uhr
Wie? Die Videos können vorab hier angeschaut werden. Danach stehen wir zur Diskussion im Wonder-Raum bereit.
In sechs Stationen möchten wir den Teilnehmenden Einblicke in das Projekt „MiMoText“ geben und einen virtuellen Raum entstehen lassen, in dem wir unsere Ziele, Ansätze und Zwischenergebnisse exemplarisch vorstellen, diskutieren und Feedback aus der Community gewinnen. In dem interaktiven Format, welches unsere Forschungsbereiche und Teilprojekte in einzelne Stationen aufgliedert, verschränken wir Projektvorstellung, Dialograum und die Sammlung von neuen Ideen ineinander.
Wir haben zu den einzelnen Stationen Videos vorbereitet und freuen uns, am 24.03.2021 von 10-12 Uhr in dem Wonder-Raum in den verschiedenen Arealen mit euch ins Gespräch zu kommen. In den Videos informiert jedes Teammitglied in etwa 3 Minuten über das jeweilige Teilprojekt von MiMoText und steht dann im Wonder-Raum an der jeweiligen Station bereit. Die Videos können als Grundlage für den Dialog dienen, aber natürlich ist es auch möglich, einfach direkt vorbeizuschauen.
Durch die Kombination aus den kurzen Impulsvideos und einem vertiefenden Dialog an jeder Station wird deutlich, wie die verschiedenen Informationsquellen und Forschungsbereiche in “MiMoText” ineinandergreifen. Es geht uns darum, neue Wege für die Analyse und Modellierung von Literaturgeschichte zu beschreiten. Anhand des “roten Fadens” thematischer Aussagen, der durch den virtuellen Raum hindurch gelegt wird, kommen alle Partizipierenden ins Gespräch über die Herausforderungen im Aufbau eines literaturgeschichtlichen Wissensnetzwerks, aber auch den möglichen Nutzen, wünschenswerte Abfragemöglichkeiten und vieles mehr. Wir sind gespannt darauf, “lessons learned” aus unserem Pilotprojekt zu teilen und erste (Zwischen-)Ergebnisse zu diskutieren.
Videos zu den sechs Stationen
Übersichtskarte zum MiMoText-Wonder-Raum
Hinweise zu Anmeldung und zur Nutzung des Wonder-Raums
- Zur Nutzung von Wonder muss nichts heruntergeladen werden, sondern es reicht aus, diesem Link zu folgen. Es werden im Anschluss einige Hinweise zur Freigabe von Mikro und Kamera gegeben und es wird ein Foto für den Avatar erstellt (das man auch austauschen kannst).
- Bitte beachten: Wonder läuft nicht auf Tablets und nicht auf allen Browsern. Das Wonder-Team empfiehlt Chrome und Edge, wir raten zu Chrome.
- Es gibt keine Anmeldefrist und keine Zugangsbeschränkung. Wir freuen uns, wenn viele Interessierte den virtuellen Weg zu uns finden.
- Um besser ins Gespräch zukommen, nutzen wir die “Icebreaker-Question”-Funktion von Wonder “Why are you here?” Die Antwort wird als Mouseover neben dem Avatar (erkennbar als Bild eines Screenshots, das beim Betreten des Raums aufgenommen wird oder ein anschließend hochgeladenes Bild) erscheinen.
- Um einer Bubble beizutreten und die Möglichkeit zu erhalten, mit anderen ins Gespräch zu treten, wird der eigene Avatar einfach zu einer bestehenden Station navigiert. Daraufhin öffnet sich ein eigener Gesprächsraum mit Funktionen, wie man sie von gängigen Videokonferenztools gewohnt ist.
- Zugang unter diesem Link.
Infos zu den sechs Stationen
An dieser Stelle möchten wir genauer darauf eingehen, was an den einzelnen Stationen zu erwarten ist. Die Übersichtsgrafik gibt einen Überblick, wie die verschiedenen Informationsquellen (Bibliographie, Romane, Sekundärliteratur), Forschungsbereiche / Research Areas und vDHd-Stationen zusammenhängen.
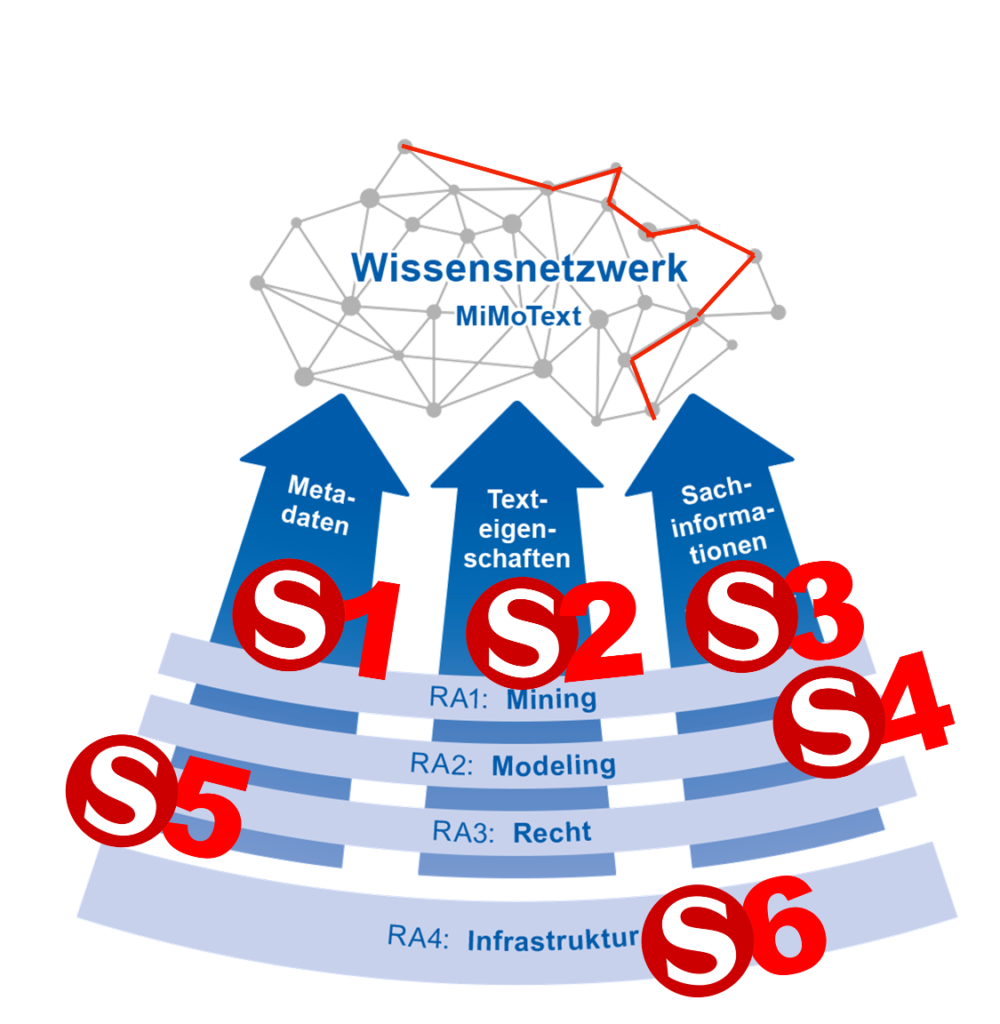
Station 1: Mining – Bibliographie
Die 1977 erschienene Bibliographie du genre romanesque français 1751-1800 enthält rund 2600 Einträge und repräsentiert die Grundgesamtheit der Romane, die Gegenstand unserer Untersuchung sind (Mylne, Frautschi und Martin 1977). Die hier dokumentierten Autor:innen und Werke mit ihren grundlegenden Metadaten bilden damit den Anker für das Wissenssnetzwerk. Da zudem für zahlreiche (aber nicht alle) Romane eine inhaltliche Verschlagwortung (u.a. zu Erzählform, Handlungsort, Protagonisten, Inhalt der Handlung und Themen oder Stil) vorliegt, können auch weitergehende Aussagen extrahiert werden und mit den aus anderen Quellen erhobenen Informationen verglichen werden. Die Bibliographie wurde von Andreas Lüschow unter Nutzung u.a. der SPAR-Ontologien in RDF modelliert (vgl. Lüschow 2019). Station 3 illustriert die Inhalte der Bibliographie und ihre Nutzung im Projekt anhand eines Beispiels aus dem Pilotprojekt.
Station 2: Mining – Romane
Der Teilbereich von “Mining and Modeling Text”, der sich mit der Informationsextraktion aus Primärtexten auseinandersetzt, stellt seinen Forschungsstand vor: Ein digitales Korpus aus französischen Romanen 1750-1800 befindet sich im Aufbau. Die Texte stammen dabei aus verschiedenen Quellen. Neben eigener Digitalisierung mittels Double-Keying-Verfahren und dem Einsatz von OCR-Software werden verfügbare Dateien aus dem Internet zusammengetragen. Alle Textdaten werden in TEI-konformes XML überführt. In einem ersten größeren Analyseschritt wurden mithilfe von Topic Modeling in dem Romankorpus vorkommende Themen ermittelt und als thematische Statements in Form von RDF-Tripeln extrahiert.
Station 3: Mining – Sekundärliteratur
Betrachtet wird Sekundärliteratur aus dem 19. und 20. Jahrhundert. Aus den Sekundärwerken werden Informationen extrahiert über besprochene Werke, Autoren etc. Als nächster Schritt nach der reinen Erfassung von Erwähnungen in Form von Named Entities sollen außerdem Aussagen über die Werke erfasst werden. Teilweise werden diese Informationen bereits der Bibliographie entnommen, wie Autor, Werk, Gattung, Erzählperspektive. Aussagen, die modelliert werden, sind z.B. spricht über oder Wertungen. Dafür werden die extrahierten Aussagen als Linked-Open-Data modelliert. Dies soll später das maschinelle Auffinden von textuellen Zusammenhängen ermöglichen. Station 2 illustriert die Extraktion und Modellierung als Linked Open Data anhand eines Beispiels aus der Sekundärliteratur.
Station 4: Modeling
Die in den ersten 3 Stationen erhobenen Daten aus heterogenen Informationsquellen werden in einer Art “Wikidata für die Literaturgeschichte” zusammengeführt. Station 4 verdeutlicht die Bedeutung des Linked Open Data-Paradigmas für die Modellierung der Entitäten und Relationen. Neben den konzeptionellen Fragen, was eigentlich die für die Literaturgeschichtsschreibung relevanten und in einer RDF-Tripel-Struktur abbildbaren Aussagetypen sind, gibt die Station exemplarisch Einblick in den bisherigen Stand der Modellierung und die Wechselwirkungen der verschiedenen beteiligten Tools (vgl. Station 6), der Nachnutzung existierender Ontologien und Standards und der angedachten Verbindung mit externen Ressourcen. Station 4 stellt im Kontext des Pilotprojekts einen visualisierten Auszug aus dem Wissensnetzwerk vor, der verschiedene thematische Aussagen, die aus den drei verschiedenen Informationsquellen gewonnen wurden, zusammenbringt.
Station 5: Recht
Das Forschungsprojekt wird von Beginn an rechtswissenschaftlich begleitet. In Station 5 soll der Modus des interdisziplinären Austauschs beschrieben werden: Es werden rechtliche Probleme identifiziert, die im Projektkontext exemplarisch auftauchen, und diese dann in Form von Handreichungen abstrahiert dargestellt. Inhaltlich zielt die interdiziplinäre Zusammenarbeit bisher darauf ab, insbesondere die urheberrechtlichen Fragestellungen bei der Einwicklung eines Wissensnetzwerkes für die Geisteswissenschaften zu ergründen. Dabei verfasste Handreichungen machen es sich zum Ziel, die rechtlichen Rahmenbedingungen beim Einsatz von Text und Data Mining-Verfahren in den Geisteswissenschaften – über den Projektkontext hinaus – darzustellen.
Station 6: Infrastruktur
Das Forschungsprojekt stellt seine Infrastruktur und genutzte Tools vor: Wir setzen zur Digitalisierung der Werke aus dem 18. Jahrhundert OCR4all ein, annotieren die Sekundärliteratur mit dem semantischen Annotationstool INCEpTION und arbeiten mit der Open Source Software Wikibase zur Modellierung eines Wissensgraphen.
Links
- Wonder-Raum zur vdhd 2021 – MiMoText in sechs Stationen
- Zenodo-Publikation: zenodo.org/record/5850778